Loss Function (Funkcja straty)
Kluczowym elementem w przypadku wykorzystania wzmocnienia gradientowego jest funkcja straty. Gradient Boosting iteracyjnie minimalizuje funkcję straty poprzez poprawianie błędów poprzednich drzew i optymalizację predykcji. Przykładowymi funkcjami straty są:
- dla regresji: Mean Squared Error (MSE) - błąd średnio-kwadratowy, który mierzy różnicę między rzeczywistymi wartościami a przewidywaniami,
- dla klasyfikacji: Log Loss – błąd logarytmiczny, który mierzy prawdopodobieństwo przypisania do złej klasy.
Model na każdym etapie wylicza gradient funkcji straty (stąd nazwa „Gradient Boosting”), który wskazuje, jak zmienić parametry, aby zmniejszyć błąd. W skrócie, Gradient Boosting stara się znaleźć kierunek największej redukcji błędu i podąża nim, poprawiając model.
Learning Rate (Współczynnik uczenia)
Learning rate to hiperparametr, który wpływa na to, jak duży krok model wykonuje przy aktualizacji przewidywań przy budowaniu nowego drzewa. Jest to liczba między 0 a 1 (zazwyczaj blisko 0.001), która skaluje wpływ każdego drzewa na ostateczne przewidywania. Niska wartość stałej uczenia powoduje, że model będzie uczył się wolniej, ale bardziej precyzyjnie i nie "przeoczy" minimum, co może wystąpić przy za dużej stałej uczenia. Zagrożeniem jest jednak możliwość utknięcia w lokalnym minimum, dlatego dobór stałej uczenia wymaga wyczucia i doświadczenia.
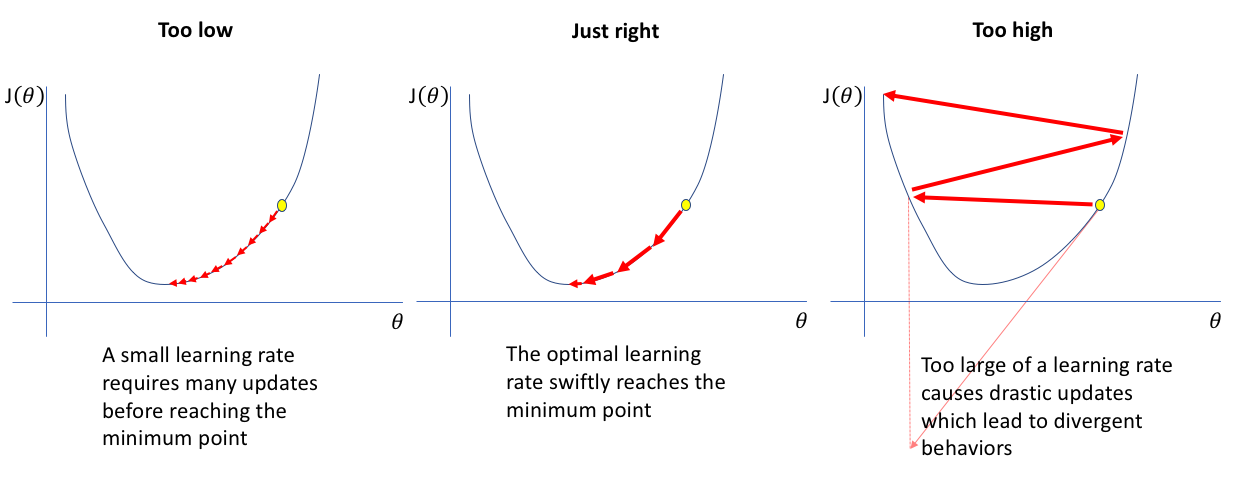
Rysunek: Porównanie jak wygląda szukanie minimum w zależności od stałej uczenia, źródło: [1]
Zatem learning rate to balans między dokładnością modelu a czasem obliczeń – zbyt wysoki może prowadzić do szybkiego przeuczenia, a zbyt niski sprawia, że model wymaga więcej iteracji, aby osiągnąć dobre wyniki.
Number of Trees (Liczba drzew)
Liczba drzew (n_estimators) w Gradient Boosting to liczba iteracji, które model wykonuje, aby poprawić swoje przewidywania. Każde drzewo, na podstawie błędów resztowych swoich poprzedników, dodaje swoje poprawki do modelu. Liczba drzew wpływa następująco na model:
- zbyt mała liczba drzew: model może być niedouczony (underfitting), ponieważ nie ma wystarczająco dużo iteracji, aby dokładnie nauczyć się zależności w danych.
- zbyt duża liczba drzew: może prowadzić do przeuczenia (overfitting) i mieć małą umiejętność do generalizacji.
Liczba drzew musi być dostrojona w połączeniu z learning rate - jeżeli stała uczenia jest niska to potrzebne jest więcej drzew, aby osiągnąć wysoką dokładność i uniknąć przeuczenia.
Overfitting (Przeuczenie)
Overfitting to zjawisko, w którym model staje się zbyt dopasowany do danych treningowych, co prowadzi do gorszej wydajności na nowych, niewidzianych wcześniej danych. Gradient Boosting, choć bardzo efektywny, może być podatny na przeuczenie, zwłaszcza gdy model zawiera zbyt wiele drzew, zbyt duży learning rate lub zbyt głębokie drzewa. Aby temu zapobiec, można zastosować następujące techniki:
- max depth (maksymalna głębokość drzewa): płytsze drzewa są mniej podatne na przeuczenie, ale wymagają większej liczby iteracji, aby uzyskać dobre wyniki.
- subsampling (podpróbkowanie): technika polega na używaniu tylko części danych do trenowania każdego drzewa, co w rezultacie powoduje, że model jest bardziej odporny na szumy i przeuczenie.
Co dalej?
Przejdź do kolejnego zagadnienia (Implementacja Gradient Boosting]) lub kliknij tutaj, aby wrócić do strony głównej tematu.